The 'KQED' Model of Scientific Discovery
At a high level, my work centers on the following construct:
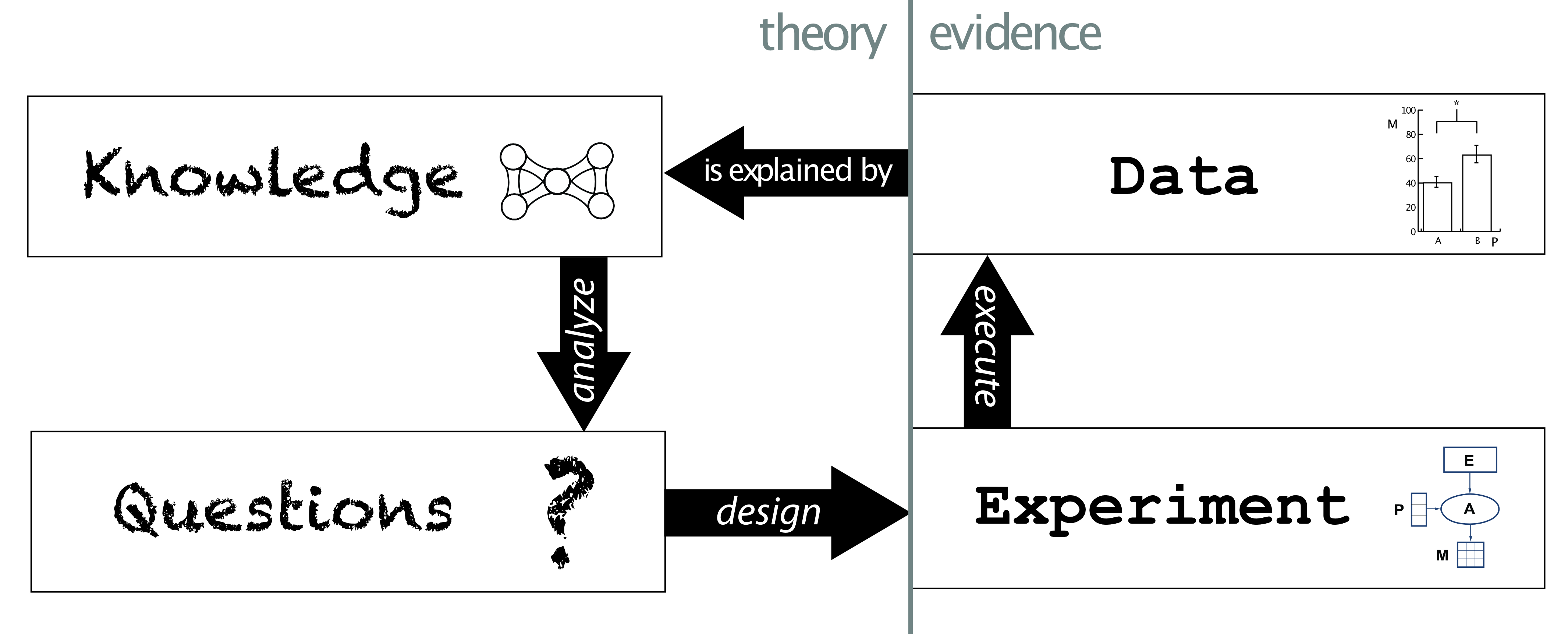
This was the centerpiece of a talk that I presented to the ‘International Neuroinformatics Coordinating Facility’ (INCF) in Stockholm in 2013 [▶ YouTube]. This presentation summarized my knowledge engineering research strategy that formed the basis of my academic work at the time. I was a Research Lead at USC’s Information Science Institute. A decade ago, my approach conceptualized scientific work as this cyclic K.Q.E.D. process that centered on the idea that we should split our viewpoint into (A) massively complex interpretive models of any given domain and (B) tractable models of the experimental methods of those domains.
Somewhat presciently, I said:
“The people who are very good at dealing with interpretations are people … who have been steeped in the background and the knowledge of the subject for 20 years. The secrets they have in the back of their head are stuff that no computer program could really represent very effectively until we build an AI system that can do science effectively.”
(paraphrased for clarity)
Amazingly, a mere 13 years later, this is no longer the case.
We now live in a world where easily-accessible AI systems are capable of advanced scientific reasoning.
I would claim that the central assertion I made in this talk still holds. It is useful to clearly distinguish between the interpretative logic used to describe biological phenomena and mechanisms (such as ‘function’, ‘phenotype’, ‘pathway’, etc.) and the underlying data and methodology that supports the designation of those mechanistic terms.
In fact, the Foundational Models being created that now form the basis of the ‘Knowledge’ part of the KQED cycle are (mostly) trained on data. Enforcing a high-level of clarity in the metadata surrounding the generation of that data (i.e., the ‘Experiment’ part of KQED) provides an important conditioning signal that could address so-called batch effects found when training models. For example, if training a model on perturbation expression data, it would important to be able to carefully detail the type, timeframe, and precise manipulation used to generate perturbations present each dataset being trained on.
Furthermore, the ‘Question’ part of the KQED cycle governs the space of available or high-value hypotheses in the space of investigation. The brilliant work of Larry Hunter investigating the ‘Ignorome’ (the body of knowledge describing our ignorance surrounding a subject) is of deep relevance here (see Callahan et al 2023) addresses this idea and is largely underinvestigated as a key concept. This aspect of the cycle informs what Andrew White of Edison Scientific calls ‘Research Taste’ (see this discussion from Latent-Space’s interview of Dr. White), which could be thought of a distillation of the perceived value of prioritizing one set of questions over another at any given time.
It is also crucial to remember that these cycles of scientific work typically occur within a given experimental paradigm - often using expertise or tools that are only understood by people from within that paradigm - and so the scientific ecosystem is a large-scale, high dimensional space with all sorts of divisions, barriers, and undiscovered regions.
My hope is that if we can leverage these elements into our use of AI agents and models in these domains, we’ll be much better at developing fully-fledged AI scientists that we can really dive into.
We’re just getting started.
References
Callahan TJ, Stefanski AL, Kim JD, Baumgartner WA, Wyrwa JM, Hunter LE. Knowledge-Driven Mechanistic Enrichment of the Preeclampsia Ignorome. Pac Symp Biocomput. 2023;28:371-382. PMID: 36540992; PMCID: PMC9782728.